
阿里新开源的FunAudioLLM项目
如果只有短短几秒的微信语音,如何才能模仿他们的声音?在当时,各种项目不是效果不好,就是无法根据这么短的输入音频进行声音模仿。不过现在,依靠 FunAudioLLM,我们终于可以实现了!

只需三秒的输入音频,提供输入文本,FunAudioLLM 可以生成具有相同音色的音频。更让人惊喜的是,项目支持跨语言语音翻译!比如你只给出了一段中文的语音,项目可以帮你生成相同音色下,粤语、日语、英语等不同语种的声音,想象一下,哪怕自己日语的五十音图都还没有认全,借助 FunAudioLLM 的 CosyVoice,你甚至可以听到自己的声音说着流利的日语!

而 FunAudioLLM 的功能远不止如此。如果我们将一本书输入给大模型,让大模型尝试理解书中各个人物的性格、情感,模拟出他们的情绪特点和音色,通过 CosyVoice 的语音合成功能,你可以得到一段旁白,其中不同的人物有不同的音色与情绪。

项目的高级功能还有很多。不知道大家有没有看过一本网络小说《十日终焉》,小说里的角色“青龙”具有分辨不出是男是女的神奇音色,我根本无法想象这个声音到底是什么样的。通过 FunAudioLLM,你可以输入两个不同音色的输入音频,项目可以合成两个音色,创造出一个可能真的从未存在的声音!甚至,你可以调整偏好,让生成出的音色更贴近某一个音源。

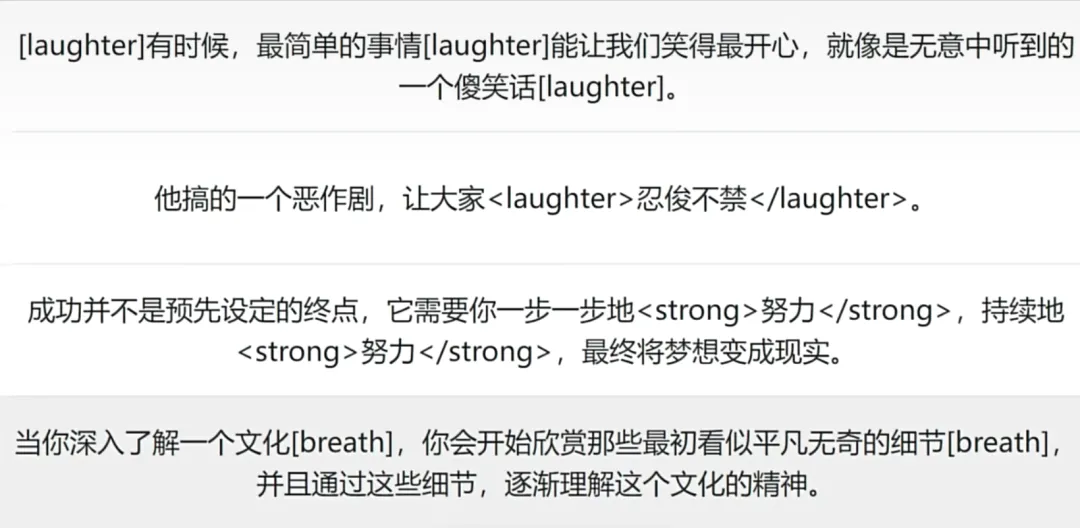
此外,先前介绍过的 ChatTTS 可以通过打标签的形式让生成出带情绪起伏的音频,比如大笑、悲伤、强调,FunAudioLLM同样能做到。还有给识别到的语音加标点符号,通过识别语音中的音乐查询到音乐的名字,都是非常实用的功能。
视频地址:
https://www.bilibili.com/video/BV18T421Y7FG
项目地址: